Martin Leslie | Research
I work with Marek Rychlik on constructing quantum error correcting codes. I am interested in a wide range of mathematics and its applications to technology. I have some knowledge of error correcting codes, information theory, quantum computing, quantum error correction, compressed sensing, Low Density Parity Check (LDPC) codes, digital communication, cryptography, elliptic curves, algebra and number theory, and stochastic processes.
This page includes a number of topics that I study, explained using only simple high school mathematics. If you follow along with a pen and paper and really take the time to try to understand what I'm saying, hopefully you'll get an idea of the kinds of things I do. I'd be interested to hear from you if you've read this and have any questions or comments. If you're an expert then skip along to the end where you'll find some words about my research.
Error correcting codes
Digital information is stored and transmitted, whether in computer hard drives or cell phone communications or many other media, as a sequence of 0s and 1s that we call bits. However this information is not stored or transmitted perfectly: there are errors caused for example by unwanted heat or by interference. Sometimes we can see or hear these errors and they aren't a big problem, but sometimes they can be catastrophic, for example crashing a computer program.
So engineers and mathematicians (starting with Hamming and Shannon in the 1940's and 50's) worked on ways to protect their important information. These error correcting codes can be understood in a variety of different ways: we will explain an example using a graphical approach.
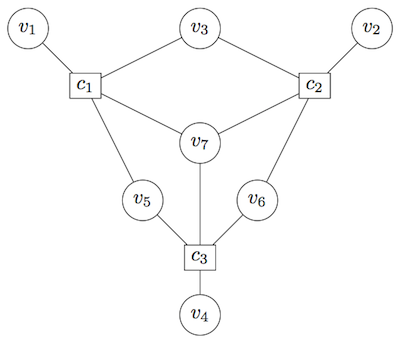
In the picture above we use circles to represent bits of information (they can be either 0 or 1). Each square is something we call a "parity check". For a string of bits to be a valid "codeword" each square needs to be connected to an even number of bits which are set to 1.
If we write the values of the seven bits in order from v1 to v7 in order then we can check that 0000000 is OK, that 1000000 is not (because c1 is not connected to an even number of bits which are 1) and for example 1011010 is a valid codeword.
In fact if you check all possible bitstrings of length 7 (all 128 of them!) you'll see that exactly 16 of them "satisfy" the checks. So we have 16 codewords for our error correcting code. Now if we match up the 16 possible bit strings of length 4 to the 16 codewords then we have have a way to communicate: pick which of the sixteen messages we want to send, convert that to a codeword, send it to the person we wish to communicate with and then they convert it back to the message.

Next we will see why these codes are error correcting. If we look at the 16 codewords we can see that no codeword can be changed to another in the list by "flipping" (i.e. changing 0 to 1 or 1 to 0) less than three digits. So if some error in transmission leads to exactly one of the bits being flipped then we can determine which codeword was sent. If more than one bit is flipped we may correct to the wrong codeword, so we can't have 100% error-free communication in any realistic example, but if our communication channel isn't too noisy then having at most one error per codeword may be a good approximation.
Quantum Mechanics
Quantum mechanics is the part of physics that describes how very small objects interact. A traditional introduction to quantum mechanics would discuss atoms and molecules, which can get quite complicated and obscure the fundamental behavior of quantum systems. So we will only discuss a simple type of abstract quantum system: the qubit.
A qubit can be either a 0 or a 1 or some combination of the two (this is part of the famed weirdness of quantum mechanics). We will describe the state of a qubit by a pair of numbers, with the sum of the squares of those numbers adding to 1 (this is also weird - but it's what the physicists say works). We can interpret the first number as "how much" the qubit is in the state 0 and the second number as "how much" it's in the state 1. More precisely: if we measure the particle (this is a technical term, the meaning of which is still somewhat mysterious even to the experts) then we measure it to be in state 0 with probability the square of the first number and 1 with probability the square of the second number. After we measure it, the particle is now 'stuck' in the state that we measured it (this is what the term 'collapsing the wave-function' means if you've heard that somewhere). It is possible to create a system of 2 qubits (or more, but we'll just talk about 2). Its state is described by four numbers: the squares of which correspond to the probability that the system will be measured to be in state 00 or 01 or 10 or 11. If you're really paying attention, you might ask "How is this different from probability being used to represent ignorance?". Well, one answer uses a fact that we haven't made clear yet: the numbers representing the states can be negative (of course when we square them to get probabilities they become positive).If we think of a state represented by the pair (x,y) then we need to have x2+y2=1. Recall that this is the equation of a circle of radius 1 and thus we can think of points on this circle as representing possible states of a qubit.
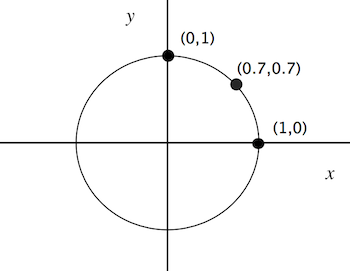
So far we haven't discussed operations that can be carried out on qubits. We require that these operations take quantum states to quantum states and are linear (i.e. operate on sums by operating on each term in the sum separately). One such operation corresponds to rotation by 45 degrees counterclockwise.
This operation takes the point (1,0) to (1/√2,1/√2) and then takes this pair to (0,1). So if we rotate the state (1,0) (representing a qubit which is definitely 0) then we get a state (1/√2,1/√2) (a qubit which is 50% 0 and 50% 1) and then rotating again gives a state (0,1) (a qubit which is definitely 1). We can think of this second rotation as leading to destructive interference - the probabilities cancel. This isn't possible in classical (i.e. non-quantum) systems.
Quantum Computation
Quantum computation was first considered quite late in the history of computing and quantum mechanics: only in the 1980's. The question that was asked is whether a computer using the kind of quantum weirdness we have discussed can be more efficient than any classical computer that we have now.
One of the most impressive answers to this question is Shor's algorithm. This algorithm is designed to factor large numbers into products of primes. Recall that a prime number is a positive whole number that is divisible by exactly two numbers: itself and one. So 15 is not prime because 15 is 5 times 3, but 17 is prime.
Very roughly, most quantum algorithms work by doing something like:
- Setting up a quantum state that represents all the possible answers to a question.
- Doing some kind of operation that leads to the wrong answers destructively canceling and the right answer being amplified.
- Measuring the state, which will give the right answer with some (hopefully high) probability.
This outline shows both the promise and the difficulty of designing quantum algorithms. A quantum state of 10 qubits can be in a combination of any of 2 to the power of 10 (i.e. 1024) states and so requires that many numbers to describe it. But when we measure the system we just get one of these states: there's no way to get all those numbers out.
Experimental quantum computing researchers are trying to build components that could be put together to make a quantum computer. Currently the best implementations of Shor's algorithm can only factor the numbers 15 or 21. Not so impressive you might say, but the theory is sound. If we can build reliable quantum computers with enough qubits then they will soon be faster at factoring than any known approach using classical computers. In particular this would break a cryptographic (i.e. secret sharing) protocol called RSA that is widely used on the internet.
Quantum Error Correction
One of the things that makes building a quantum computer difficult is quantum noise, in the form of unwanted operations or measurements that the environment performs on your quantum computer. Quantum error correction is an attempt to use ideas from classical error correcting codes to correct this quantum noise.
Imagine we have some quantum information (i.e. some number of qubits in a particular state) in our computer. We consider two types of noise which we can think of as acting on one qubit at a time. The first type of noise we will represent by a function X which acts on states by X(a,b)=(b,a) and the second type of noise we will represent by a function Z with Z(a,b)=(a,-b). So the X error flips the probabilities of 0 and 1, while Z doesn't change the probabilities, only the phase. As we've seen the possibility that these numbers representing states can be negative is crucial to understanding quantum mechanics so these Z errors are a real quantum problem - they don't occur in classical error correction.
After these errors occur on some number of qubits we try to correct them. Notice that if we know where the X and Z errors then we can correct them by applying the X and Z functions to the appropriate qubit (each of X and Z undo themselves).
We use classical error correcting codes of the type we discussed earlier to correct the X and Z errors separately. Recall that measuring a quantum state can cause the state to collapse so we need to measure the qubits carefully. We have to measure them in such a way that we only receive information about which error happened, not what the information was before the error. We also need to be able to measure each qubit for X errors as well as Z errors. This puts constraints on the pair of classical error correcting codes which we can use. This method of quantum error correction that I have been describing is the use of CSS codes, named for their creators Calderbank, Shor and Steane.
My Research: Hypermap-Homology Codes
My dissertation research is a new method of constructing quantum error correcting codes. I will now get more technical in describing it. CSS codes are quantum stabilizer codes which are defined by a pair of classical codes with parity check matrices HX and HZ such that HXHZT=0.
One way to construct CSS codes takes the matrices HX and HZ to be matrices representing boundary operators of some homology chain complex with F2 coefficients. For example, Kitaev's toric code can be understood as follows. Embed a square grid graph on a torus and take HX to be the matrix representing the boundary operator that takes edges to vertices and HZ the boundary operator that takes faces to edges. Then HXHZT=0 because the boundary of a boundary is zero. It can be proved that the m by m toric code has parameters [n,k,d]=[2m2,2,m] i.e. it can store 2 qubits worth of information in 2m2 physical qubits and it can correct any errors on up to (m-1)/2 qubits.
For my codes instead of embedding a graph in a surface I embed a hypergraph (a generalization of a graph where an edge can be connected to more than two edges) in a surface. I prove theorems that allow us to determine the parameters of the resulting codes depending on the embedded hypergraph (also called a hypermap). As an example of why this might be useful if we construct a code from a hypermap which is a straightforward generalization of the toric code we can achieve parameters [n,k,d]=[1.5m2,2,m]. So we can store the same number of qubits with the same error correcting capability using less physical qubits.
If you are interested in this research you can read my defense talk and my PhD dissertation.